cat articles/sqlite-duckdb-vaporetto
Japanese Full-Text Search in SQLite and DuckDB with Vaporetto
With the rise of various agents, embedded databases such as SQLite and DuckDB have become increasingly interesting because they run without a server and persist as local files. I looked into how these databases handle Japanese full-text search. SQLite FTS5 can search with trigrams, but out of the box it does not seem to provide search specialized for Japanese vocabulary.
There are approaches using Lindera, but this time I made extensions that embed Vaporetto, a lightweight and fast tokenizer implemented in Rust.
- SQLite + Vaporetto
- DuckDB + Vaporetto
Vaporetto uses a pointwise prediction method, judging character boundaries with a linear classification model. It can be used with a dictionaryless model, though dictionary-based models also exist, so it can keep the model size small depending on the use case.
I also made a technical demo that runs entirely in the browser, combining DuckDB and Vaporetto to perform full-text search sorted by BM25 relevance score. When the number of target texts is small, the benefits of full-text search, which stays fast as the number of documents grows, and BM25, which considers term frequency and document length, are less visible.
As another example, I tried building article search for this blog, secon.dev, with SQLite + FTS5 + Vaporetto. For about 2,700 articles, BM25 search usually ran in around 3 ms.
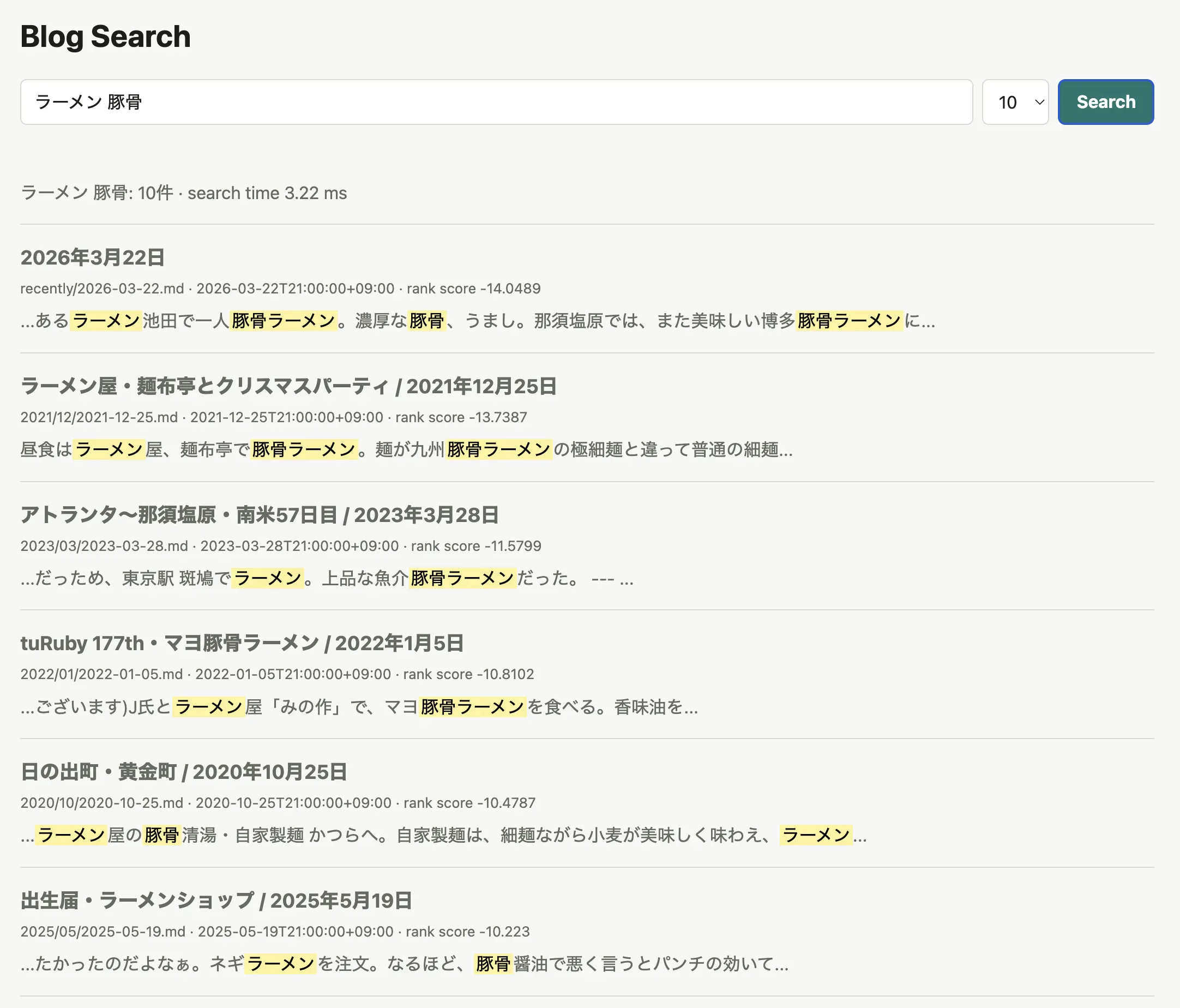
This makes casual Japanese full-text search possible with SQLite and DuckDB, so I think it can be useful when the use case fits.
Update: I received a helpful comment from Kudo-san, a leading expert in morphological analysis. For full-text search, word segmentation by pointwise prediction is not well suited because inconsistency can be a problem. That makes sense.
Pointwise word segmentation is not well suited to full-text search. Especially without a dictionary, context-dependent segmentation is unavoidable, which increases the risk of missed matches. I discuss this in my book on morphological analysis.
Context dependence means, for example, that the segmentation of the phrase "morphological analysis" is uniquely determined without being affected by surrounding context. It is important that the query segmentation can be reproduced in the document. A unigram language model satisfies this condition. Accuracy is sacrificed, but consistency is guaranteed.