cat articles/japanese-reranker-v2
Releasing Small, Fast, and Practical Japanese Rerankers: tiny, xsmall, small, and base v2
I released very small Japanese reranker models, japanese-reranker-tiny-v2 and japanese-reranker-xsmall-v2. In information retrieval systems, rerankers improve the precision of search results, but model size and compute cost are practical challenges.
🆕 Update, 2025-07-10: I also added moderately small rerankers, japanese-reranker-small-v2 and japanese-reranker-base-v2.
These models are built with minimal layer counts and parameter counts, and they run at practical speed even on CPU and Apple silicon. This makes it possible to improve RAG system accuracy without expensive GPU resources, and should make them useful for edge deployment and production environments that require low latency. In evaluation, they achieve competitive scores even compared with larger models.
- https://huggingface.co/hotchpotch/japanese-reranker-tiny-v2
- https://huggingface.co/hotchpotch/japanese-reranker-xsmall-v2
- https://huggingface.co/hotchpotch/japanese-reranker-small-v2
- https://huggingface.co/hotchpotch/japanese-reranker-base-v2
What Rerankers Are, and Why Small Rerankers Matter
A reranker is a model that evaluates the relevance between a question, or query, and documents, then reorders the documents by relevance. Its strength is that it can evaluate complex relationships that ordinary embedding search may miss. In particular, CrossEncoder architectures take the query and document as one input pair, allowing finer-grained nuance and contextual understanding.
Small rerankers matter for several reasons. First, a reranker must evaluate every combination of a query and candidate document. Reranking 100 candidate documents requires 100 model inferences. Smaller models therefore directly improve throughput and reduce latency.
Small models can also run in resource-limited environments. They can run at realistic speed on CPU-only environments, edge devices, and mobile devices, improving the practicality of RAG systems. In server environments, they also reduce GPU memory usage and make it easier to share GPU resources, improving cost efficiency.
Small rerankers therefore provide important benefits in speed, cost, and resource efficiency, and can play a useful role in practical RAG systems.
Benchmark Performance
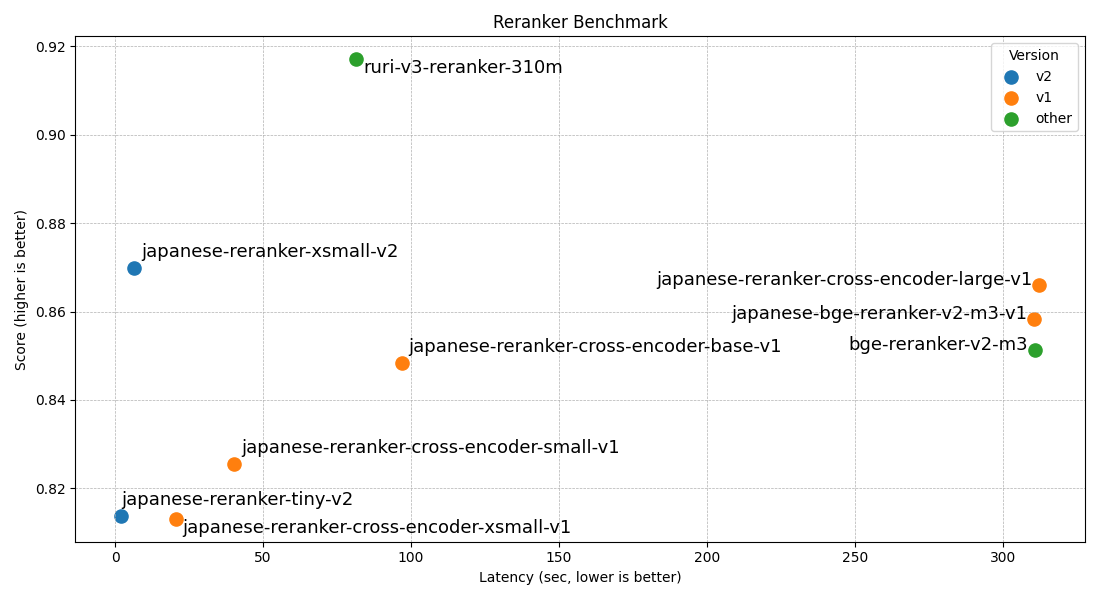
The benchmark results are below. Considering their model size, the tiny and xsmall v2 models perform quite well. Among larger models, ruri-v3-reranker-310m is clearly strong. The fact that these high-performing models are based on ModernBERT likely contributes to the improvement.
Japanese models have learned the tendencies of JQaRA, a quiz-style dataset, which puts bge-reranker-v2-m3 at a disadvantage. This is also an example of how much a reranker score can improve when the domain task is learned appropriately.
| Model name | avg | JQaRA | JaCWIR | MIRACL | JSQuAD |
|---|---|---|---|---|---|
| japanese-reranker-tiny-v2 | 0.8138 | 0.6455 | 0.9287 | 0.7201 | 0.9608 |
| japanese-reranker-xsmall-v2 | 0.8699 | 0.7403 | 0.9409 | 0.8206 | 0.9776 |
| japanese-reranker-small-v2 | 0.8856 | 0.7633 | 0.9586 | 0.8385 | 0.9821 |
| japanese-reranker-base-v2 | 0.8930 | 0.7845 | 0.9603 | 0.8425 | 0.9845 |
| japanese-reranker-cross-encoder-xsmall-v1 | 0.8131 | 0.6136 | 0.9376 | 0.7411 | 0.9602 |
| japanese-reranker-cross-encoder-small-v1 | 0.8254 | 0.6247 | 0.9390 | 0.7776 | 0.9604 |
| japanese-reranker-cross-encoder-base-v1 | 0.8484 | 0.6711 | 0.9337 | 0.8180 | 0.9708 |
| japanese-reranker-cross-encoder-large-v1 | 0.8661 | 0.7099 | 0.9364 | 0.8406 | 0.9773 |
| japanese-bge-reranker-v2-m3-v1 | 0.8584 | 0.6918 | 0.9372 | 0.8423 | 0.9624 |
| bge-reranker-v2-m3 | 0.8512 | 0.6730 | 0.9343 | 0.8374 | 0.9599 |
| ruri-v3-reranker-310m | 0.9171 | 0.8688 | 0.9506 | 0.8670 | 0.9820 |
Inference Speed
The table below shows inference time for reranking about 150,000 pairs with the Hugging Face Transformers library. Tokenization time is excluded, so this is pure model inference time. I used an M4 Max for MPS and CPU measurements, an RTX 5090 for GPU, and FlashAttention 2 for ModernBERT-family models on GPU.
japanese-reranker-tiny-v2 and xsmall-v2 are clearly fast. ruri-v3-reranker-310m is also fast for its size, likely because FlashAttention 2 is effective. Other models can also use FlashAttention 2 through tools such as text-embeddings-inference, and may run faster than in this evaluation.
| Model name | Layers | Hidden size | Speed (GPU) | Speed (MPS) | Speed (CPU) |
|---|---|---|---|---|---|
| japanese-reranker-tiny-v2 | 3 | 256 | 2.1s | 82s | 702s |
| japanese-reranker-xsmall-v2 | 10 | 256 | 6.5s | 303s | 2300s |
| japanese-reranker-small-v2 | 13 | 384 | 15.2s | ||
| japanese-reranker-base-v2 | 19 | 512 | 32.5s | ||
| japanese-reranker-cross-encoder-xsmall-v1 | 6 | 384 | 20.5s | ||
| japanese-reranker-cross-encoder-small-v1 | 12 | 384 | 40.3s | ||
| japanese-reranker-cross-encoder-base-v1 | 12 | 768 | 96.8s | ||
| japanese-reranker-cross-encoder-large-v1 | 24 | 1024 | 312.2s | ||
| japanese-bge-reranker-v2-m3-v1 | 24 | 1024 | 310.6s | ||
| bge-reranker-v2-m3 | 24 | 1024 | 310.7s | ||
| ruri-v3-reranker-310m | 25 | 768 | 81.4s |
I also publish models converted to ONNX for CPU use, so with ONNX and ARM quantized models, they should be usable even in edge environments such as Raspberry Pi.
Short Technical Report
The training data for japanese-reranker-tiny-v2, xsmall-v2, small-v2, and base-v2 is based on the dataset used to train hotchpotch/japanese-splade-v2, plus hard negatives and some additional private data. The large improvement over v1 likely comes from using ruri-v3-pt-30m, a ModernBERT-based model pretrained for the target task, using several times more data than v1, and extracting higher-quality data with hard negatives, including filtering positives and negatives with scores from various rerankers.
For the Tiny model's parameter extraction source, I evaluated sbintuitions/modernbert-ja-30m and cl-nagoya/ruri-v3-pt-30m. ModernBERT alternates global attention and local attention layers. For example, modernbert-ja-30m has 10 layers, where [0,3,6,9] are global attention layers and the others are local attention layers.
At first I expected all global attention layers to work best, but including layers 3, 6, and 9 generally made results worse. Including layers close to the output also made results worse. The table below shows reranking evaluation results for models trained on the same dataset. Results including layers close to the output, such as 6 and 9, were much worse and training was stopped early, so they are not included. Layer 0 alone did not produce useful performance.
| name | JQaRA | miracl | jsquad | JaCWIR |
|---|---|---|---|---|
| modernbert-ja-30m + full layers | 0.7261 | 0.8095 | 0.9752 | 0.9420 |
| modernbert-ja-30m + layer 0,2,4 | 0.6455 | 0.7185 | 0.9588 | 0.9265 |
| modernbert-ja-30m + layer 0,2 | 0.6171 | 0.6784 | 0.9516 | 0.9155 |
| modernbert-ja-30m + layer 0 | 0.2515 | 0.4416 | 0.3172 | 0.0738 |
| ruri-v3-pt-30m + full layers (= xsmall-v2) | 0.7403 | 0.8206 | 0.9776 | 0.9409 |
| ruri-v3-pt-30m + layer 0,2,4 (= tiny-v2) | 0.6455 | 0.7201 | 0.9608 | 0.9287 |
| ruri-v3-pt-30m + layer 0,1,3 | 0.6405 | 0.7124 | 0.9552 | 0.9211 |
| ruri-v3-pt-30m + layer 0,3 | 0.6177 | 0.6619 | 0.9482 | 0.9076 |
From these results, I published ruri-v3-pt-30m as xsmall, and ruri-v3-pt-30m + layer 0,2,4 as tiny. small-v2 and base-v2 are based on ruri-v3-pt-70m and ruri-v3-pt-130m, respectively. Model merging slightly improves performance, but I did not use it this time.
Closing
This article introduced the small, lightweight, and practical Japanese reranker models japanese-reranker-tiny-v2, japanese-reranker-xsmall-v2, japanese-reranker-small-v2, and japanese-reranker-base-v2. The tiny and xsmall models run at practical speed on CPU and Apple silicon, and can improve search accuracy for local RAG systems without requiring expensive GPU resources. Running them on GPU also enables fast responses.
Recent high-performance encoder models such as ModernBERT make it easier to build practical models with stronger performance. I hope this article contributes to the further development of Japanese language processing technology.